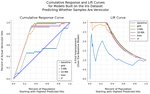
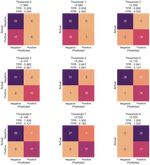
Explore the world of k-Nearest Neighbors classifiers (k-NN-C) with this comprehensive project, where we build a high-performing model using the Iris Dataset and Python. Learn about the inner workings of k-NN-C, lazy learning, and the importance of Euclidean distance in generating predictions. Dive into the process of constructing the model, including preprocessing the dataset and using cross-validation splits. Achieve an impressive mean accuracy of 96.67% with 5-fold cross-validation and discover the model’s potential applications in various classification tasks, along with future research recommendations.